
It might also save it from shit controllers and cables which ECC can’t help with. (It has for me)
Avid Amoeba
- 18 Posts
- 1.01K Comments
Joined 1 year ago
Cake day: July 5th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Unless you need RAID 5/6, which doesn’t work well on btrfs
Yes. Because they’re already using some sort of parity RAID so I assume they’d use RAID in ZFS/Btrfs and as you said, that’s not an option for Btrfs. So LVMRAID + Btrfs is the alternative. LVMRAID because it’s simpler to use than mdraid + LVM and the implementation is still mdraid under the covers.

 28·1 day ago
28·1 day agoIt is marketing and it does have meaningful connection to the litho features, but the connection is not absolute. For example Samsung’s 5nm is noticeably more power hungry than TSMC’s 5nm.
And you probably know that sync writes will shred NAND while async writes are not that bad.
This doesn’t make sense. SSD controllers have been able to handle any write amplification under any load since SandForce 2.
Also most of the argument around speed doesn’t make sense other than DC-grade SSDs being expected to be faster in sustained random loads. But we know how fast consumer SSDs are. We know their sequential and random performance, including sustained performance - under constant load. There are plenty benchmarks out there for most popular models. They’ll be as fast as those benchmarks on average. If that’s enough for the person’s use case, it’s enough. And they’ll handle as many TB of writes as advertised and the amount of writes can be monitored through SMART.
And why would ZFS be any different than any other similar FS/storage system in regards to random writes? I’m not aware of ZFS generating more IO than needed. If that were the case, it would manifest in lower performance compared to other similar systems. When in fact ZFS is often faster. I think SSD performance characteristics are independent from ZFS.
Also OP is talking about HDDs, so not even sure where the ZFS on SSDs discussion is coming from.
Doesn’t uBlock Origin already have a Manifest V3 version of the extension?
To add a concrete example to this, I worked at a bank during a migration from a VMware operated private cloud (own data center) to OpenStack. In several years, the OpenStack cloud got designed, operationalised, tested and ready for production. In the following years some workloads moved to OpenStack. Most didn’t. 6 years after the beginning of the whole hullabaloo the bank cancelled the migration program and decided they’ll keep the VMware infrastructure intact and upgrade it. They began phasing out OpenStack. If you’re in North America, you know this bank. Broadcom can probably extract 1000% price increase and still run that DC in a decade.
Why would MS not use this opportunity to also hike the prices of their equivalent offerings? 1000% increase leaves a lot of room for an increase while still being cheaper.

Not sure where you’re getting that. Been running ZFS for 5 years now on bottom of the barrel consumer drives - shucked drives and old drives. I have used 7 shucked drives total. One has died during a physical move. The remaining 6 are still in use in my primary server. Oh and the speed is superb. The current RAIDz2 composed of the shucked 6 and 2 IronWolfs does 1.3GB/s sequential reads and write IOPS at 4K in the thousands. Oh and this is all happening on USB in 2x 4-bay USB DAS enclosures.
That doesn’t sound right. Also random writes don’t kill SSDs. Total writes do and you can see how much has been written to an SSD in its SMART values. I’ve used SSDs for swap memory for years without any breaking. Heavily used swap for running VMs and software builds. Their total bytes written counters were increasing steadily but haven’t reached the limit and haven’t died despite the sustained random writes load. One was an Intel MacBook onboard SSD. Another was a random Toshiba OEM NVMe. Another was a Samsung OEM NVMe.
Yes we run ZFS. I wouldn’t use anything else. It’s truly incredible. The only comparable choice is LVMRAID + Btrfs and it still isn’t really comparable in ease of use.
Yup. All of these “solutions” that sound original are known. The reason we don’t apply them isn’t because we don’t know how to solve these issues, it’s because capital has pulled the handbrake. This is the problem we have to solve. All the other problems fall downstream and will magically start getting solved if we can release the handbrake. If we’re not talking about how to reduce regulatory capture, we’re not taking about real solutions.
While there are voluntary shit-ass PMs, you can only afford to be not a shit-ass PM because the org isn’t squeezing you for all it can. Once it does, you’d have to make similar decisions. If you quit because you don’t agree with the way things are going, a compliant shit-ass PM will take your place, or no PM, and the people would end up in the place the parent described.
When you learn that publicly traded companies are mostly obliged to squeeze as much work from you while paying as little, then all the all the puzzle pieces fall into place and all of what you said starts to make perfect sense.
Make an alt-alt over VPN and tells us more. 😁
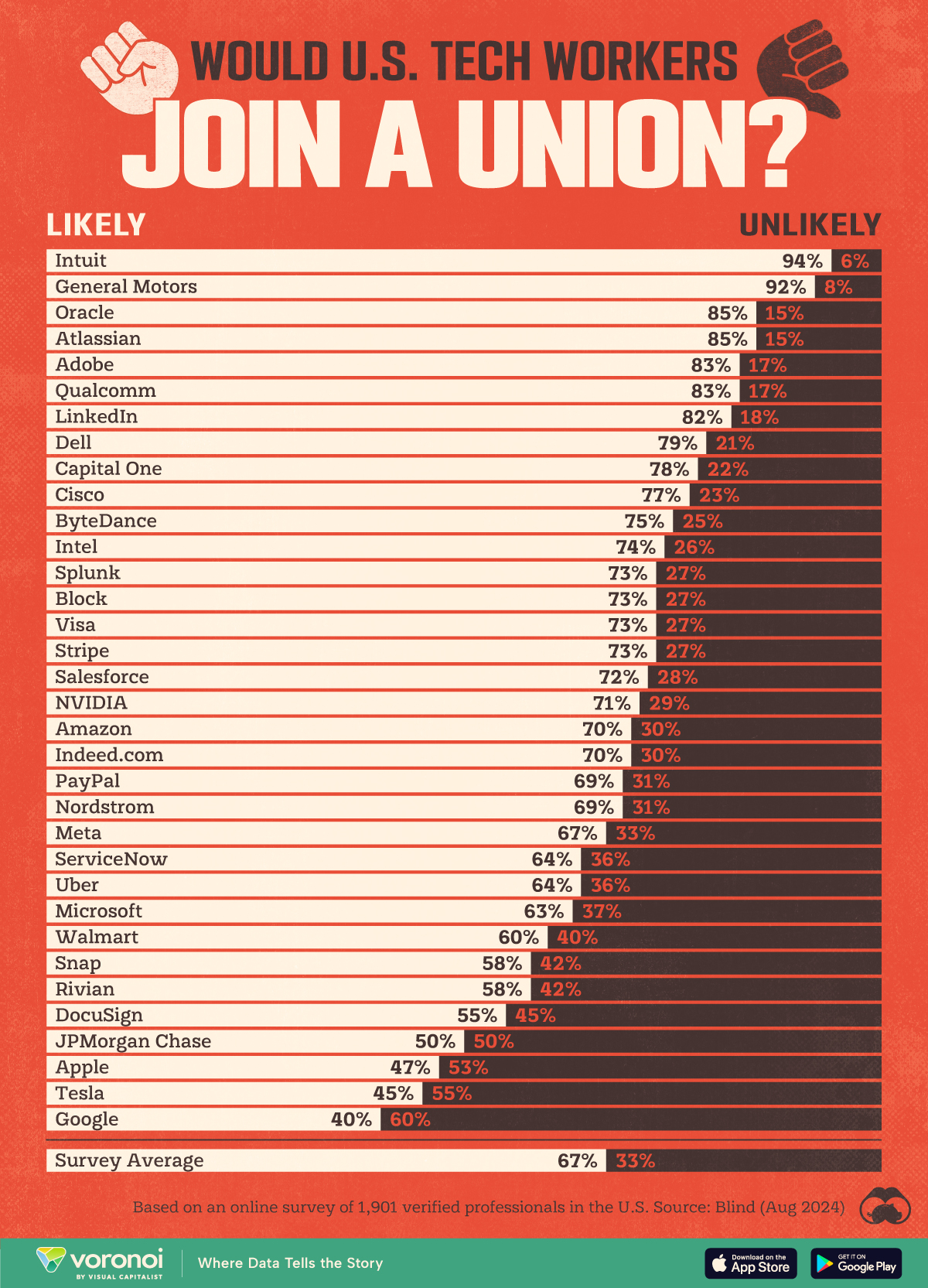
I guess not much if I were an Intuit employee and significantly if I were at Apple. 😄
“that’s not good, but we’ll have to fix the underlying issue after we finish implementing the new UI the design team is excited about”
Classic. Once I landed in a team who’s been woken up every night, often multiple times a night for several years. The people left were so worn down, burnt out and depressed that it was obvious just by looking at them. The company has cut the team to the bone and the only people left were folks that didn’t have the flashy resumes to easily escape. They had drawn up plans to fix the system years ago. BTW, none of that was disclosed to me until I had signed up and showed up for work and asked who are those miserable looking people over there. “That’s your team” the man replied.
Those compensation requirements would basically make it financially impossible to have someone on-call or they’d just have to hire people for those hours and say they are normal working hours
These are not the only options. Here are some others:
- Ensuring the on-call load is shared more evenly so that everyone is woken up under the painful limit
- Fixing the broken shit that keeps waking people up, which they keep ignoring because “it’s low priority”
- Hiring people for a night shift, appropriately compensated for their diminished health and other life impacts. The union can ensure such positions aren’t paid the same as normal work hours while not being prohibitively expensive. Night shifts are a standard thing in some occupations
Something’s telling me most orgs where 2 is an option would go with that. Related to that - increases in labor compensation is what forces companies to spend money on capital investment that increases productivity - read new equipment, automation, fixing broken shit, etc. If there are cheap enough slaves to wake up during the night, doing this investment is “low priority” (more expensive) and isn’t done.
That’s not the case the parent was asking about though. They were asking whether they can do more than what’s in their job description. Not whether someone else is obliged to do more.
I don’t doubt your experience and it’s totally fine by me. That’s how they want to run their workplace, that’s the way they run it. It doesn’t mean you’re gonna make yours like that. It’s unlikely that a software org would be run like that. At the end of the day unions are democratic institutions where their members decide how to do these things. Because of that, your current org would likely be run the way you and your colleagues want to run it. Not in some bizarre way that Las Vegas convention workers do. :D



{kind=link}
Found the Canadian.