
15·
4 days agovendor whose major investors include Thiel’s Founders Fund
To be fair, most SaaS vendors probably have investors associated with the nerd reich
vendor whose major investors include Thiel’s Founders Fund
To be fair, most SaaS vendors probably have investors associated with the nerd reich
Hey there, cutter.
If you’re really after the deconstruction aspect, then I’m not sure there’s a whole lot out there. But if you zoom out to the level of “methodically tinkering with a system that requires careful attention”, there’s a lot of those.
Hardship Breakspacer is part of a (pseudo-)genre known as “dad games”.
On the “hardcore nerd” end of the spectrum, there’s even:
A little more chill:
Edit: Or for the “scraping my way through out in space” vibe, but less tinkering:
Edit 2: Also, repair is probably an applicable theme:
The loot boxes require skill? How?
Found this study, but no mention of skill influencing the outcome of opening a loot box.
Star Ocean

Not sure about Apple-mediated payments, but you can usually support the creator more directly and get an ad-free RSS feed that you can plug into the Podcasts app and it Just Works™. Usually ends up being a better deal for the creator, too.
Nix, but I’d only recommend it if you share my same brand of mental illness
I’m always on unstable. Any time I try to stick to stable, I invariably need something-or-other that’s only on unstable.

Like AI companies care about business ethics
only a tool
“The essence of technology is by no means anything technological”
Every tool contains within it a philosophy — a particular way of seeing the world.
But especially digital technologies… they give the developer the ability to embed their values into the tools. Like, is DoorDash just a tool?

Lemme share the tea for anyone who isn’t aware:
Those additional requests will reuse the existing connection, so they’ll have more bandwidth at that point.
I see what you’re saying, but the fact that it can be ambiguous is actually what makes it so useful to fascist organizers.
They thrive on phrases that allow them to wink at each other when they want to, but claim innocence if someone calls them out.
14kB club: “Amateurs!!!”
https://dev.to/shadowfaxrodeo/why-your-website-should-be-under-14kb-in-size-398n
a
14kBpage can load much faster than a15kBpage — maybe612msfaster — while the difference between a15kBand a16kBpage is trivial.This is because of the TCP slow start algorithm. This article will cover what that is, how it works, and why you should care.
The original source was much more sensible.
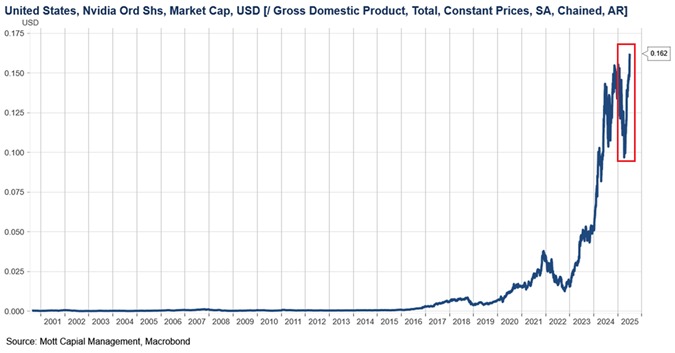
The comparison makes sense for evaluating whether you’re over-invested in something. Like, if Nvidia suddenly poofed out of existence, would it seriously be worth 16% of everything the whole country makes in a year to get it back?
Owning a car that’s worth 16% of your yearly income sounds reasonable, no matter what your actual income is. A Pokemon card collection that’s 16% of your income is probably too risky, no matter what your actual income is.
Also, GDP is a decent scale to use for charting investment in a productivity tool, because if GDP ramped up at the same time as investment then it looks less like a bubble, even if they both ramp up quickly.
But that’s not what we see. We see a sudden and volatile shift, nothing like the normal pattern before the hype.
Jimmy Wales: Libertarian that ended up creating perhaps the most successful collectivist project of all time.
Its supposedly open source??
NPM users: “…and?”
AI bubble will pop by 2030. (I fucking hope.)

Not my own invention, but I’m glad you appreciated it: https://www.thenerdreich.com/